
Riconoscere l’innovazione grazie al Machine Learning sul corporate web italiano

Chiedersi cosa sia innovativo presuppone l’esistenza di un quadro di riferimenti condiviso. Citando una delle interviste di Umberto Veronesi possiamo dire con lui che: “l’innovazione si fonda sulla capacità di trasgredire”
Tuttavia trasgredire indica un procedere oltre ed implicitamente una direzione ed un verso. Il verso è il futuro o, meglio, la narrazione dominante sul futuro. E non vi è nulla di più suggestivo che il mondo delle startup. Dunque possiamo riformulare la domanda in questi termini: che cosa caratterizza e definisce il mondo delle startup rispetto al panorama delle aziende italiane? L’appello a quali temi e il riferimento a quali business lo definisce?
L’archetipo di azienda innovativa è la startup: questo è dunque l’assunto. La definizione di innovatività a questo punto un calcolo statistico sui tratti salienti delle aziende iscritte all’omonimo registro.
Una questione astratta si tramuta in un problema di Information retrieval: trovandoci di fronte ad un catalogo di aziende italiane, ciascuna con una sua descrizione, e conoscendo tra queste le startup, che segnale emerge, dissonante, dal loro profilo? Quale lezione può essere appresa per riconoscere l’innovazione anche laddove non si presenta con il crisma dell’ufficialità?
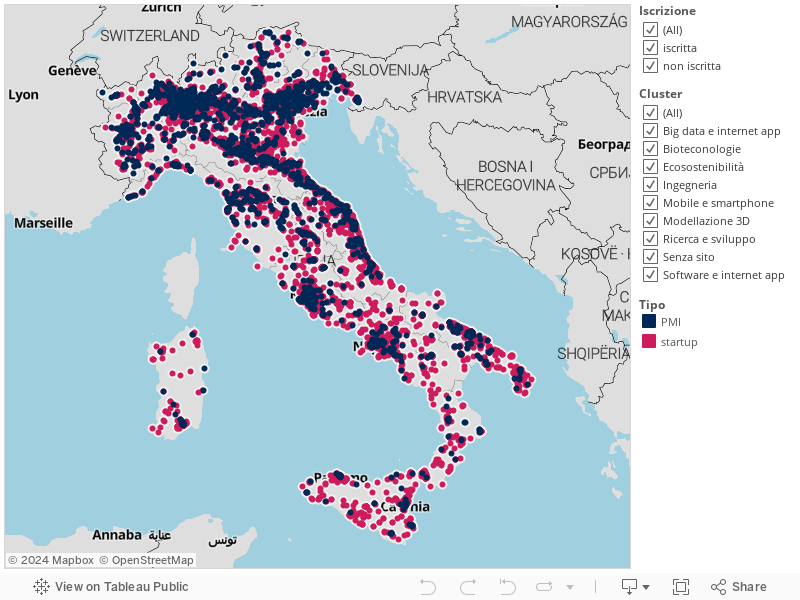
Abbiamo affrontato la questione assieme a Cerved ed il lavoro è confluito in un capitolo dell’annuale rapporto sulle PMI. L’analisi ha richiesto dati dal corporate web italiano (la collezione di descrizioni menzionata sopra), l’utilizzo di strumenti di text analytics (Dandelion API) per l’estrazione di informazioni chiave dai siti web e l’impiego di tecniche di Machine Learning per allenare quello che potremmo definire come un classificatore di innovatività, nel senso più preciso di “adesione al business delle startup”. Ne è risultata una mappa più comprensiva ed articolata del mondo delle piccole e medie imprese innovative italiane: ben 10 mila sono quelle che sono risultate innovative per il nostro radar ma non iscritte alle sezioni startup o PMI innovative del Registro Imprese.
I tratti salienti dell’innovazione
Siamo partiti navigando con un crawler il web italiano ed abbiamo associato a più di 670 mila aziende il loro sito ufficiale dal quale abbiamo ricavato informazioni condensate nelle schede azienda che si possono consultare in Atoka. Tra queste informazioni vi sono le parole chiave che cercano di qualificare un’azienda attraverso una lista di “concetti” o, più precisamente, pagine di Wikipedia con il loro sistema di connessioni reciproche, metadati etc. SpazioDati, per fare un esempio comodo, si porta appresso: Big Data, Dati, Google Knowledge Graph, Marketing, Semantica, Web Semantico, Apprendimento Automatico etc. (Per inciso: in questo articolo c’è tutto ciò: i Big Data come prodotto della navigazione massiva del web, il (nostro) grafo della conoscenza ottenuto collegando informazioni web, social ed ufficiali da fonte Cerved, l’analisi semantica ed il Machine Learning per generare previsioni e classificatori.)
Mettendo insieme tutte le parole chiave delle startup se ne ricava un gran vociare. I temi più ripetuti sono anche “classici”: tecnologia, software, progettazione, commercio, informatica sono i più frequenti. Se però accostiamo questo rumore al vociare di tutte le aziende italiane impariamo a distinguere le differenze: prestiamo attenzione alle anomalie, alle peculiarità del coro startup e ci accorgiamo ad esempio dell’anomala percentuale di startup che si occupa di Internet of Things e che una fetta considerevole delle aziende che si occupano di Big Data in Italia sono startup. Fuor di metafora, in statistica vi è un intero arsenale di strumenti per riconoscere quanto vi è di significativo in uno sottoinsieme selezionato da una popolazione di partenza: chi-square, mutual information etc. Nel nostro caso la popolazione di partenza è l’universo delle aziende italiane munite di sito web ed il sottoinsieme quello delle startup dal registro.
A questo punto il concetto di startup si materializza come una lista di parole, ciascuna con un suo grado di significatività. La visualizzazione ideale, tanto canonica quanto esatta, è quella della word-cloud ove il corpo va con la rilevanza:

Si ritrovano le parole d’ordine di un mondo noto però l’elenco ed i pesi sono redatti senza alcuna arbitrarietà e si basano sulla rappresentazione che le startup danno di loro stesse nei siti web.
Prendere le distanze dalle parole
Ora si può essere indotti a ritenere che l’esercizio si riduca a confrontare le parole chiave di ciascuna azienda con la nuvola qui sopra, strizzando gli occhi per vedere se c’è una benché minima sovrapposizione. Ma ci sono più cose nei siti web delle aziende italiane, di quante ne sogni la nostra filosofia. Anziché Big Data un’azienda potrebbe voler enfatizzare il concetto di Data Science oppure le tecnologie utilizzate (e.g. Apache Hadoop, Oracle): ve ne sono per ciascuna di queste fattispecie[1]. Non possiamo essere limitati né manichei quindi dobbiamo imparare a calcolare una distanza più ragionata tra il baricentro semantico di un’azienda e la nostra nuvola di parole: dobbiamo definire una metrica nello spazio delle parole.
Il modo più semplice di definire una metrica in un insieme astratto è mappare i suoi oggetti in uno spazio che una metrica la possiede. Per costruire questa immersione abbiamo utilizzato word2vec, un algoritmo di vettorializzazione che proietta le parole in punti in uno spazio vettoriale a dimensione ridotta (rispetto al numero di parole nel vocabolario). Tale algoritmo apprende similarità e semantica da un corpus testuale (idealmente ampio e ridondante) analizzando co-occorenze e prossimità una frase per volta. Intuisce che Machine Learning possa venir sostituito talvolta da Pattern Recognition, e quest’ultimo da Big Data e allora ne inferisce pure che Machine Learning e Big Data abitano uno spazio semantico ridotto e così via. Tutto un insieme di parole/concetti (decine di migliaia) viene trasformato in un insieme di punti in uno spazio vettoriale nel nostro caso a 300 dimensioni: in questa intimità (perché 300 dimensioni non sono poi tante se si sta descrivendo il mondo delle idee) l’insieme delle parole si arricchisce di relazioni e di una metrica. Rimane da chiarire una questione: il corpus. Noi abbiamo utilizzato il testo del corporate web italiano: in altre parole l’algoritmo ha imparato un linguaggio che emerge dal web e dalle aziende in particolare: lo stesso mondo su cui poi deve predicare.
Questa operazione permette di ragionare in termini geometrici: sappiamo misurare la distanza tra due parole come misureremmo quella tra due città ed individuare un addensamento di termini (cluster) come si riconosce una metropoli con la sua cintura di comuni periferici dal finestrino di un aeroplano. Per rendere l’idea eseguiamo una brusca riduzione di dimensionalità e proiettiamo alcuni di questi punti da uno spazio a 300 dimensioni su di un piano. (A lato di alcuni vi è l’etichetta della parola corrispondente.)

Divide et Impera
Si intravedono, anche se compresse dalla proiezione, alcune zone con un chiaro timbro: in basso a destra la zona, coesa, relativa al mobile (tecnologie: Android, ma anche pratiche: Mobile Marketing); in alto a sinistra quella che fa riferimento a fonti di energia rinnovabili e a basso impatto. E’ impossibile immaginare che un’azienda possa collocarsi vicino ad uno spettro così ampio di business: bisogna dunque operare un clustering ed individuare dei nuclei omogenei di parole e poi, di fronte a ciascuna azienda, chiedersi quanto si avvicini ad ognuno di essi.
L’algoritmo Agglomerative Clustering è un metodo bottom-up che procede aggregando insiemi di punti in modo da minimizzare la distanza media tra le coppie di cluster. Un simile algoritmo ha bisogno di un’indicazione sul numero di cluster desiderati. Maggiore è il numero, più alta è la risoluzione di pensiero: se un’area semantica collassa su di una sola parola chiave saremo più rapidi a riconoscerla ovunque vi imbattessimo; d’altra parte, maggiore è il numero e più la tassonomia si fa complicata e la classificazione meno pratica. La giusta misura è ricavata applicando un’euristica nota come Metodo del Gomito: immaginate di disegnare il grafico della variazione della compattezza dei cluster ottenuti all’aumentare del loro numero, tale curva scenderà inesorabilmente ma con un’andamento che sovente forma un gomito (ove la derivata prima compie un considerevole salto). In altre parole, aumentando il numero di cluster si guadagna in breve sulla loro coerenza interna, proseguendo, poi, ci si accanisce senza ottenere un guadagno sostanziale in questi termini.
Così facendo noi abbiamo individuato 8 cluster che abbiamo etichettato a questo modo:
- Big data e internet app
- Software e internet delle cose
- Ricerca e sviluppo
- Modellazione 3D
- Mobile e smartphone
- Ecosostenibilità
- Ingegneria
- Biotecnologie
Essi rivelano le anime principali del business startup in Italia.
Calculemus
Di seguito, di ogni azienda, considerate le sue parole chiave ed il loro baricentro, possiamo osservarne la collocazione relativamente a ciascun cluster. Un’azienda può essere vicina alla modellazione 3D ed anche sviluppare app integrate o meno come la startup 48H; oppure lavorare nell’informatica ma occuparsi di biotecnologia come lo spin-off dell’Università di Pavia Engenome; infine può essere semplicemente lontano abbastanza da ciascun cluster da non meritare l’attributo innovativa.
Tali misure danno origine a degli score di similarità: banalmente, più la distanza è ridotta, maggiore lo score. Ecco come appaiono le distribuzioni dei vari score nella popolazione delle aziende italiane.

Ci sono almeno tre momenti in cui lungo il processo abbiamo dovuto scegliere delle soglie: nel numero di parole chiave da inserire nella nuvola, in quello dei cluster e nel definire una soglia per ciascuno di questi score. Nel primo caso ci siamo limitati ad un’osservazione diretta, nel secondo abbiamo applicato l’euristica del gomito, in questo terzo proviamo a far dipendere la scelta dalla “qualità” dei cluster.
Dobbiamo dunque decidere quanto vicina dev’essere un’azienda al cuore di un cluster per essere considerata omologa. In termini astratti ed in parte ambigui: quanta innovazione basta nei vari settori per essere innovativi tout court?
Rispetto al centro di ciascun cluster le parole chiave si dispongono come le frecce attorno ad un bersaglio. Per giudicare l’abilità del tiratore si può calcolare la somma dei quadrati delle distanze di ciascun tentativo dal centro; la stessa misura, nel nostro contesto descrive quanto sia coeso l’insieme di parole che definisce un cluster. Ipotizziamo infatti che ciò possa influenzare negativamente la precisione nella classificazione: più un cluster è sparso, meno affidabile è il corrispettivo score e più dev’essere stringente la soglia da scegliere. I nostri cluster, rispetto a questo indicatore, hanno profili molto diversi, come si può vedere nell’istogramma qui riportato.
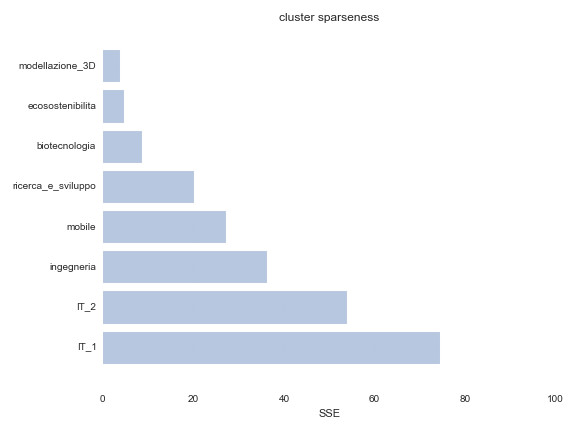
Una seconda cosa balza agli occhi ad uno sguardo più analitico: sembra esserci una dipendenza tra tali valori e la forma della curva di distribuzione degli score. Le curve più “disperse” sono in corrispondenza dei cluster più compatti e viceversa. Il calcolo del coefficiente di correlazione (di Spearman) tra la deviazioni standard di tali curve e la misura di coesione del cluster non lascia dubbi: 0,928571.
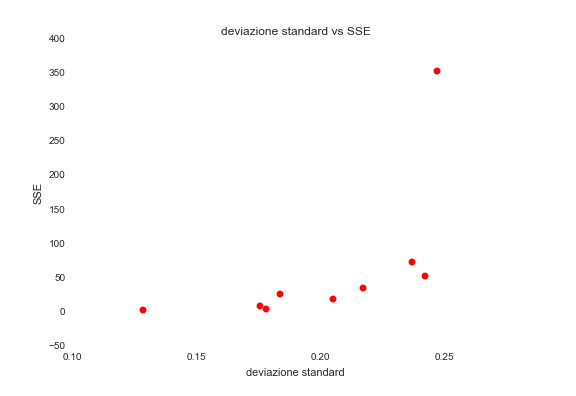
In ultima analisi perciò, essere esigenti nel caso di un cluster sparso si traduce nella scelta di una soglia proporzionale alla deviazione standard della distribuzione dello score corrispondente. Questo in letteratura è esattamente uno dei modi in cui si scovano gli outliers, le anomalie! (Più precisamente si sceglie un valore che dista dalla mediana un determinato numero di volte la deviazione standard.) Ed in fondo di questo si tratta: rintracciare tra le aziende italiane quelle che emergono e si distinguono dalla maggioranza nel loro slancio verso uno specifico aspetto dell’innovazione.
Nel novero delle aziende innovative abbiamo infine incluso tutte quelle con almeno uno score, tra gli 8 disponibili, al di sopra della soglia stabilita.
Quasi 6 mila tra le risultanti soddisfano pure i criteri dimensionali richiesti per l’iscrizione al registro delle startup e possono essere chiamate a buon diritto cripto-startup. Per una qualche ragione, limiti di informazione o consapevolezza, si trovano a non godere dei benefici del riconoscimento ufficiale pur avendone le potenzialità[2]. Altre 4 mila all’incirca sono semplici PMI.
L’innovazione ha una dinamica che sembra esorbitare in parte dai censimenti ufficiali. Rimane l’esigenza, che è al contempo una sfida, di tracciarne una mappa, la quale possa essere utile tanto a soggetti privati interessati all’investimento o a partnership quanto alle istituzioni pubbliche che hanno in parte l’onere di assecondare, quando non addirittura guidare, lo sviluppo di un comparto cruciale.
[1] – In tutto il post gli esempi non escono da un cilindro ma si riferiscono ad evidenze reali nei dati e nei modelli.
[2] – Altri requisiti necessari, quali i Criteri opzionali per rilevare il carattere di innovazione tecnologica non posso essere validati facilmente tramite informazioni ricavate dal web.